前情提要: 昨天透過了 web 的開發者模式找到 mp3 的實際音檔,但整個過程都是手動操作,有什麼辦法才能爬取到全部的音檔呢?
一開始我的想法是
但後來在裡面搜尋了一下"2023.12.31-19.00.00-S.mp3"發現,音檔的資訊其實在一開始載入這個頁面的時候就已經在 audioView?id=68350,裡面寫得清清楚楚了
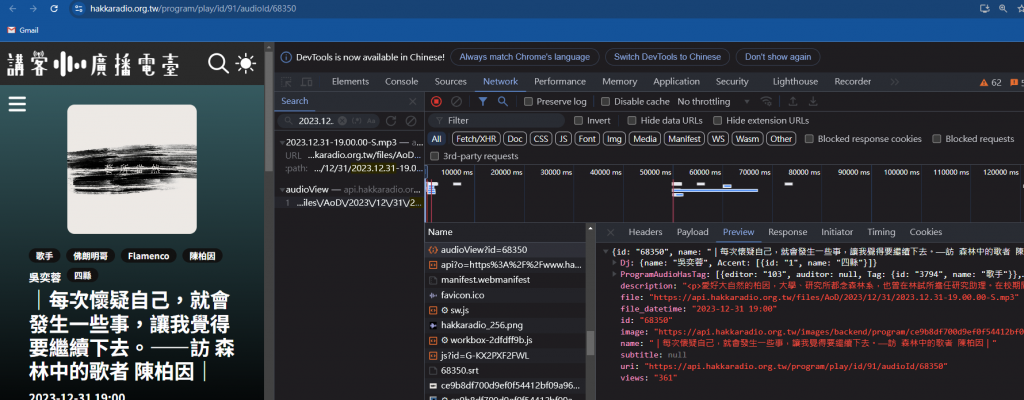
所以流程變成
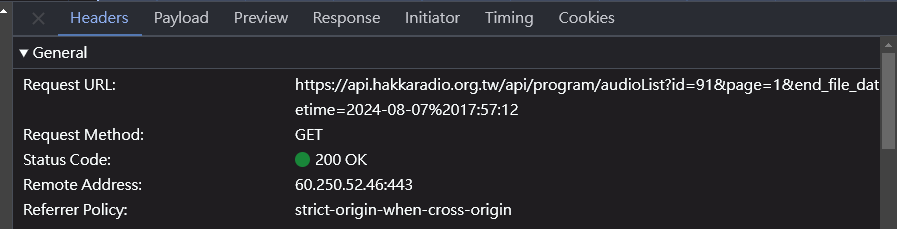
基本上按照這個流程去寫 python 就大功告成收工,但當我返回主頁時發現,他在主頁的時候就已經把那頁的 5 個節目資料存在 audioList?id=91&page=1,他的 url 為https://api.hakkaradio.org.tw/api/program/audioList?id=91&page=1&end_file_datetime=2024-08-07%2017:57:12 ,
點到下一頁發現這個 url 基本上只修改了 page
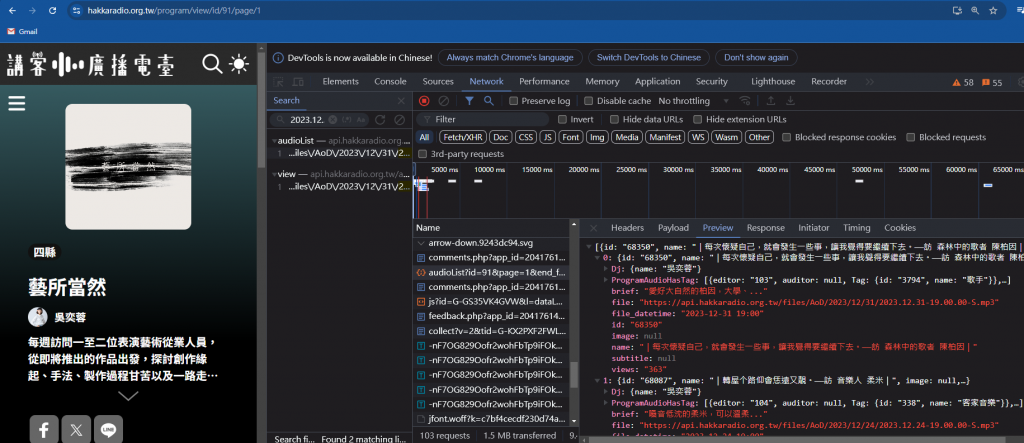

所以最後流程化簡成以下:
import requests
import json
import time
import random
spk_arr = {}
for i in range(1, 49):
base = f"https://api.hakkaradio.org.tw/api/program/audioList?id=91&page={i}"
# 直接使用request去得到audioList
response = requests.get(base)
text = response.text
data = json.loads(text)
try:
# 抽取出每個DJ的名字和mp3的連結
dj_file_list = [(item['Dj']['name'], item['file']) for item in data]
for dj, file in dj_file_list:
if dj not in spk_arr:
spk_arr[dj] = [file]
else:
spk_arr[dj].append(file)
time.sleep(1)
except:
print(f'error in {i}\n')
# print(f"DJ: {dj}, File: {file}")
with open('mp3_urls.txt', 'w', encoding = 'utf-8') as f_i:
for spk, urls in spk_arr.items():
for url in urls:
f_i.write(f'{spk}\t{url}\n')
今天就先到這囉~ 明天會把下載的 code 補上。


 iThome鐵人賽
iThome鐵人賽